Time zone bugs driving you to despair?
Adding time turns your queries into tentacled monstrosities?
Struggling to choose the best way to store history?
Time is a pain to deal with. Even though I’ve been working a lot with time series for the last decade or so, handling time never got easy. There’s always one more thing that trips you up. For example, this simple query doesn’t do what you’d intuitively expect it to do:
select *
from users
where now() - created_at < interval '1 year';
Can you spot the problem? Actually, this query isn’t going to return any users created more than 360 days ago! (There’s a good reason for this once you understand how intervals work in Postgres.)
Here is another subtlety: I noticed that many developers think that now() returns current time - but that’s not correct! (It returns the timestamp at the start of the current transaction.)
Even handling dates and times is not straightforward, because of the complicated motion of our planet combined with the sometimes haphazard superstructure of different calendars, time zones, daylight saving time and various conventions for slicing and dicing time periods. There’s a long list of things that may not be quite what you expected.
Then comes a day when your company gets a customer in another country, or your software has to present project data to users in different parts of the world, or you have to keep track of future events for globetrotting users of your applications. This is where time zone support comes into the picture.
As Patrick McKenzie put it:
“If you’ve ever wanted to play What Fresh Hell Is This for a few years, I recommend building any product with times seen by 2+ people each.”
Time zones can be a source of countless bugs, partially because a lot of people “misunderestimate” them. I’ve seen that some developers think that a time zone is just a constant offset, or that the timestamp with time zone type actually stores the time zone, or that countries change their time zone during daylight saving time.
Your queries start getting peppered with fun bits like this:
select timestamp '2017-08-13 00:00:00' at time zone 'Australia/Sydney' at time zone 'UTC';
Even this single line presents a lot of questions. Why is at time zone used twice? Are we converting from Australian time to UTC or vice versa? Why do we need UTC anyway?
Many developers find time zones to be a pain, and after working with them they either want to run away screaming or they write a manifesto to abolish time zones (which wouldn’t make things any easier, by the way).
Time handling has many levels of complexity
Once you get adept at wrestling time zone code, you’re on level two, but it turns out that you’re still only at base camp and the peak of this learning curve is somewhere above the clouds, because there are at least two more levels of complexity awaiting you.
The four levels of time handling are:
- Basic storage of dates/times and time based calculations.
- Support for time zones.
- Storing records about things that are in effect for a period of time (like pricing, employment, contracts and many, many other things).
- Keeping track of the history of changes to data across multiple tables.
The third and fourth level are about working with what’s called temporal data.
Fortunately, there’s been research in this area going back many decades, and there’s a book by Richard Snodgrass called “Developing Time-Oriented Databases” that goes in depth on the techniques for working with temporal data.
Unfortunately, the book was published in 1999, when Postgres was still in its infancy, so the examples are in a prehistoric dialect of SQL and instead of Postgres we get examples for DB2 and Oracle 8.
To give you an idea, consider this example. Suppose you provide software as a service, so you are storing information about the customers’ plans. Your service also allows customers to buy extra storage, with the pricing linked to the plan they’re on.
So, to find out the price at a particular point in time, it would be a simple join:
select plan, storage_size
from cust_plans
join cust_storage using (cust_id)
where cust_id = $1
Now imagine that you would like to find out how much a customer has paid you in the last year (a totally reasonable, basic kind of request). In order to allow for this question to be asked, you need to store the history for each customer, something like this (the green line shows the start of the period in question):
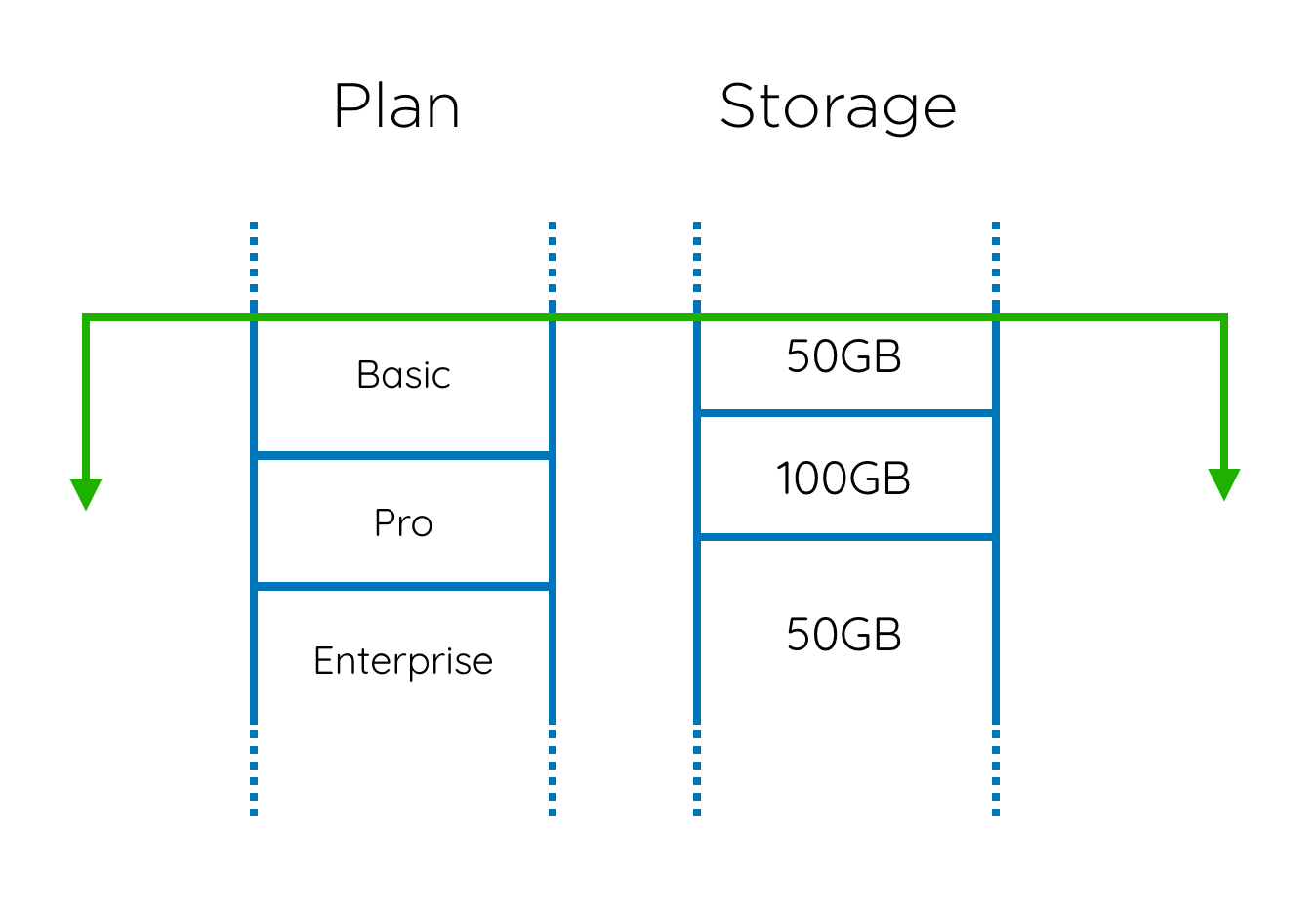
So, the customer stays on a plan for a period of time and then upgrades or downgrades. They also upgrade and downgrade the extra storage, and the overlap gives you 5 periods with different pricing which need to be summed up.
Suddenly, we’re not in Kansas anymore, and we can’t just do a join to get this result. We need to calculate these 5 periods based on the records in both tables.
This isn’t all! What if we can also apply discounts for a period of time? It could look something like this:
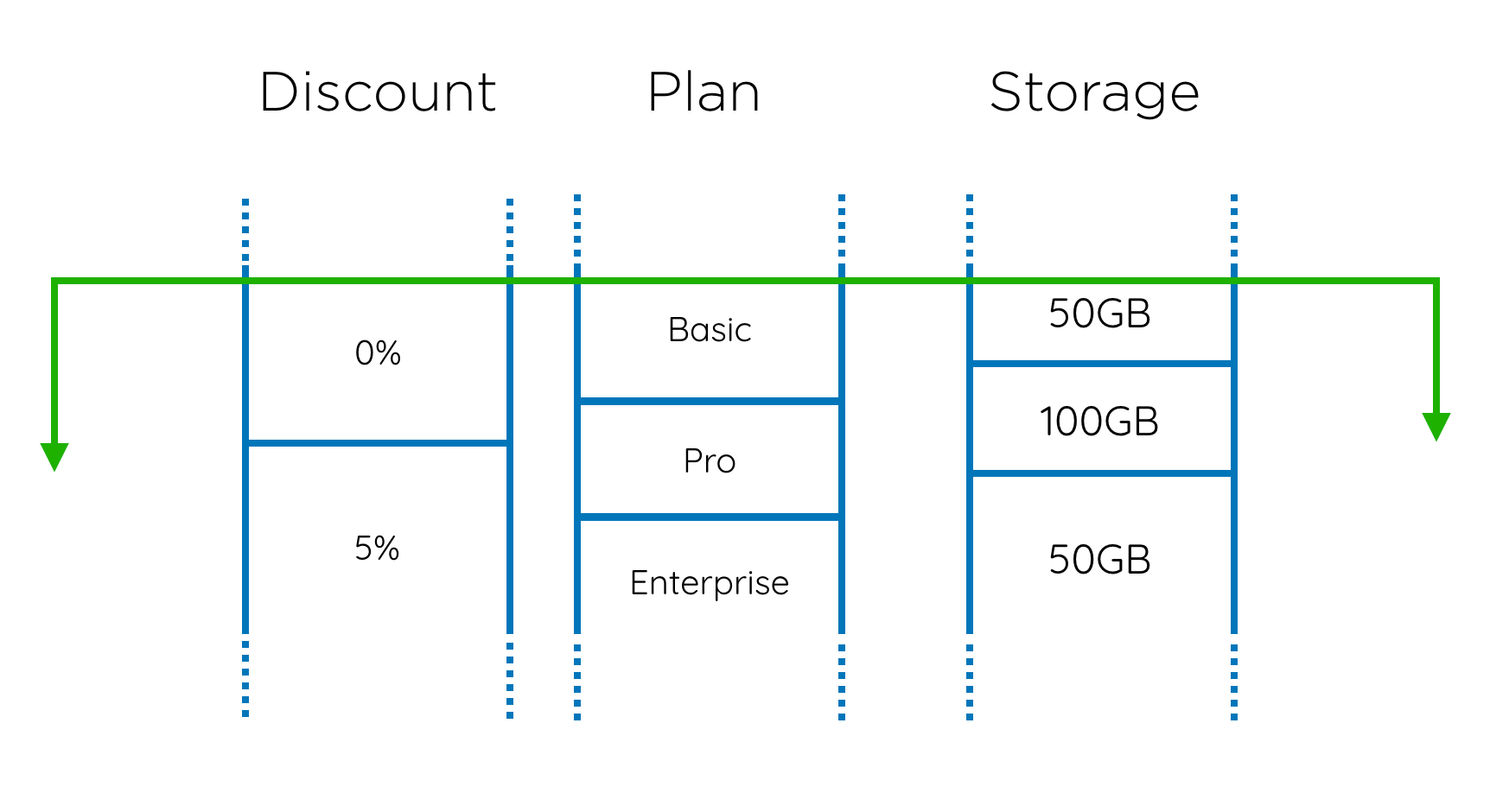
Since human operators set the discount, it’s possible that they make a mistake, so we also need the ability to reverse or amend the discounts. But, for billing and audit purposes, we need to retain all of the history of discounts, including incorrect discounts and the periods that they applied for. Imagine that you put a discount in place, the invoice went out to a customer, and then you realise the rate was wrong and you correct it - the next invoice needs to include a corresponding adjustment. Start thinking about the queries this obscure little procedure requires, and you should get a healthy feeling of dread.
Handle time without being driven to madness
Can you manage all this stuff without being driven crazy by the bugs and complexity? Yes - if you use the right techniques from the start rather than reinventing decades of research on your own.
My book, “PostgreSQL: Time and Temporal Data” will help you avoid the pitfalls and blind alleys, giving you a crash course at all the four levels I outlined:
- Date and time storage and time based calculations.
- Time zones, DST and related calculations.
- Storing records about things that are in effect for a period of time (like pricing, employment, contracts and many, many other things).
- Keeping track of the history of changes to data across multiple tables.
It will provide you with a structured approach for managing any kind of time-related data in the database. Postgres provides a solid set of tools, and you will learn how to use them to maximum advantage.
I know you may not find this subject as fascinating as I do, and you probably just want to get on with the job of adding time support to your database, so I kept the book super focused.
Here is what you will find in the book:
Table of contents
1. Introduction …… 5
2. Getting Started with Dates, Times and Durations …… 8
- Date type
- Time type
- Timestamp type
- Interval type
- Calculations
- Date operators
- Date functions
- Conversions between dates and strings
- Time operators
- Time functions
- Conversions between times and strings
- Timestamp operators
- Timestamp functions
- Conversions between timestamps and strings
- Date & timestamp gotchas
- Interval operators
- Interval functions
- Conversions between intervals and strings
- Summary
3. Working with Ranges, Current Time and Sequences …… 38
- Ranges
- Date Range
- Range Functions
- Range Operators
- Timestamp Range
- Time Range
overlapsOperator- Current Time or Thereabouts
generate_series- Summary
4. Dealing with Time Zones …… 59
- Time Zones
- How time zones are defined
- Time zone database
- Time zone summary
- Time Zone Aware Types
timestamptz- Specifying the timezone
- Calculations
timetz/time with timezonetstzrangetimestampvstimestamptz
- Calculations Using
at time zone - Things to Watch Out for
- DST
- Time zone abbreviations
- Other Storage Scenarios
- Local times
- Dates
- Future times
- Local time across timezones
- Summary
5. Keeping Track of Changing Entities …… 75
- What’s the Problem, Really?
- Avoiding Temporal Tables
- Recording the time of latest change
- Denormalisation
- Keeping a log
- Defining Temporal Tables
- User-defined time
- Valid time and transaction time
- Transaction time tables
- Valid time tables
- Bitemporal tables
- SQL:2011 Temporal Features
- Summary
6. Querying and Maintaining Temporal Data …… 102
- Techniques for Working with Time Values
- Aggregation of time values
- Making queries independent of current time
- Calculating time between rows
- Allen’s interval relations
- Coalescing overlapping ranges
- Finding gaps in a set of overlapping ranges
- Querying Temporal Data
- Time slice queries
- Sequenced queries
- Non-sequenced queries
- Modifying Temporal Data
- Current modifications
- Sequenced modifications
- Performance Considerations
- Indexing
- Reducing input set
- Speeding up reads
- Speeding up writes
- Summary
7. Interacting with Client Applications …… 135
- Sending and Receiving Dates and Times
- Date and time range selection
- Time zones on Windows
- Client clocks
- Concurrent Modifications
- Synchronising Data with Clients
- Dealing with Duplicates
- Using Postgres to Help with Testing
- Slowing down responses
- Generating randomised data
- Summary
8. Managing Time Related Configuration …… 147
- Server and Client Config
TimeZoneDateStyleIntervalStylelc_timelog_timezone
- Time Zone Abbreviations
- IANA Time Zone Database
- Summary
What this book is not
I’m going to assume that you are already familiar with Postgres, you have it installed and you are comfortable with tasks like creating databases, tables, writing queries and changing database server configuration. If you are new to PostgreSQL, then I recommend reading an introductory book or going through some tutorials first.
This book is not about SQL as described in the SQL standard. It is focused on the functionality implemented in PostgreSQL, which may not be everything defined in the standard, and which is sometimes additional to what’s in the standard. For example, SQL:2011 defines support for temporal tables, but at the point of publishing this book, Postgres doesn’t adhere to the standard in this regard.
I’m also going to touch on some tricky subjects like performance and interacting with client applications. The thing about them is that it’s very hard to give one-size-fits-all answers and solutions - otherwise this book wouldn’t be necessary as the database would just do the right thing automatically! Performance in particular is a huge subject that would require a book of its own to cover fully. So think about this book as providing some ideas, and some avenues for further exploration on those topics.
If that’s not enough to solve your problems - then congratulations! It means you have some interesting engineering challenges on your hands, and I hope you enjoy solving them, using this book as a stepping stone along the way.
“PostgreSQL: Time and Temporal Data”

Still need to know more? Check out the sample.
I may update the book from time to time if I find mistakes or typos. You’ll get these updates for free.
Remember: there’s no risk in buying. If you are not satisfied with the book, let me know within 30 days of purchase and I will send you a refund.