Sooner or later in the life of a complex code base, somebody will come up against coupling between parts of the code and say: “I know! Let’s reduce coupling by introducing message passing.” And thus a Trojan horse will be let into the walls of your code base: this may well create more problems than it solves.
My introduction to message passing happened in a large embedded C++ codebase where this mechanism was used somewhat extensively. It was probably put in place in order to manage dependencies between modules/classes as in C++ that had a significant effect on build times. It seemed like a great architectural scheme on the surface: a class just had to implement a particular interface and voila!, it could send and receive messages without knowing anything about other classes.
It was not a good idea for that system though.
As message passing spread through the code base, implementations became entangled despite being nominally independent. It became harder to understand how parts of the system affected each other, particularly in the presence of message loops.
I have since encountered other mechanisms for passing messages: Phoenix framework PubSub, CAN bus for vehicle ECUs, C++ Boost Signals library, AWS SQS and SNS and so on. The more I encountered them, the more cautious I became about using them.
Please note that in this post I’m talking about asynchronous message passing. Erlang/Elixir’s message passing is another mechanism I’ve used but I didn’t include it in the list above as it’s a (very clever) mix of sync/async.
Most of the time, you want our system to look something like this, neatly organised and easy to follow:
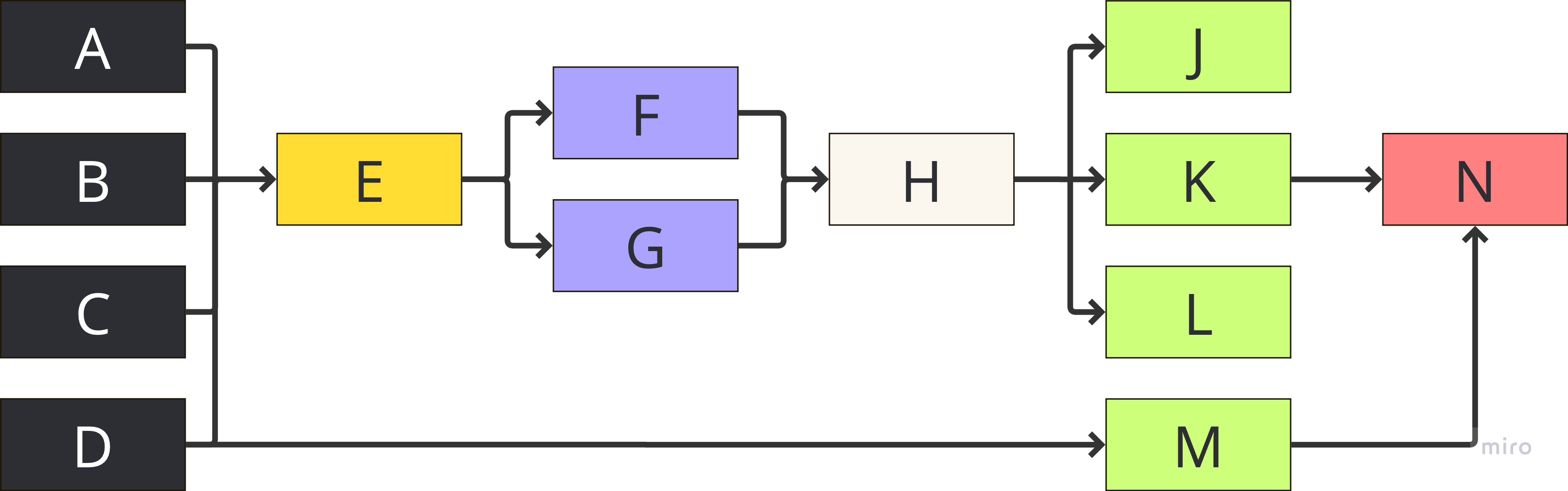
But what you get with message passing could well end up looking this:
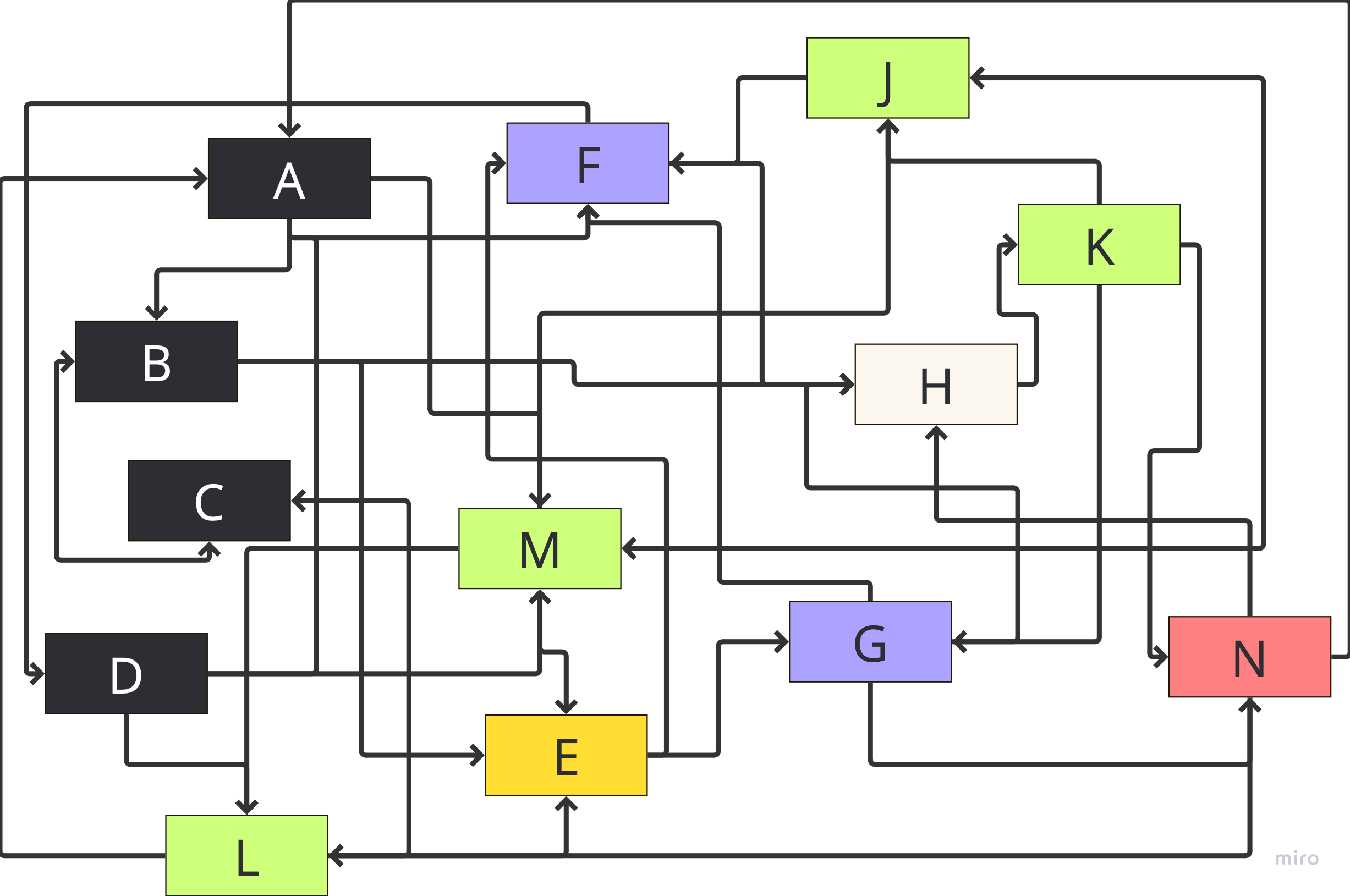
Generally, message passing architectures have a number of potential advantages:
- Removal of direct dependencies between parts of the system.
- It’s “easy”: you just need to know the format of the message and you can send it to any receiver in the system.
- Centralisation of message handling (via some type of message bus) with attendant benefits.
- Fan-out and multicast capabilities (a single
publishcall can result in messages being sent to multiple receivers). - Scalability potential (messages can be buffered, components can be distributed more easily etc.).
- Fault tolerance (senders and receivers don’t necessarily have to be available at the same time, for example).
- Simplified testing in some scenarios (as long as you can construct a message, you can test the receiver, for example).
It’s important to understand that just because the interaction mechanism between components got replaced to remove direct dependencies, it doesn’t mean that they have become truly independent. While some properties of the system may have been improved, all the complexity (and more) of the interaction between components is still in place.
I’d like to highlight that message passing comes with many tradeoffs and downsides as well:
- Synchronous interaction is replaced with asynchronous which results in more complex implementations.
- Message passing is “spooky action at a distance” as an action in a component can be triggered by anything in the system. This makes it harder to understand how the data flows and how the system operates, particularly in dynamic languages where messages can be constructed without a direct, searchable reference to a message ID or type.
- Undesirable interactions such as loops can be introduced and be difficult to detect as they can traverse many components (which additionally may not even have any obvious relation between them) rather than just two components.
- Much more complicated debugging, especially in distributed contexts.
- Ossified, difficult to change message-based APIs due to the complexity of unstructured interaction.
- Additional complexity: solving message ordering issues, providing backpressure, reliably operating message queues, dealing with message processing failures (what if the sender needs to know?) etc.
Beyond the immediate complications, I think it’s worth thinking about the influence this new mechanism will have on the developers and the system: how will the introduction of this mechanism affect the choices developers make? How will the architecture be reshaped into the future as a result? Any powerful, general purpose mechanism is likely to be applied far beyond the initial intent. (Sure, you could try to put rules in place to prevent misuse, but it’s better to avoid the problem altogether if you can.)
Message passing by default enables the system to grow into a big ball of interaction spaghetti where everything talks to everything else, making it harder to change, maintain or optimise the system. It nudges the system in the direction of making all the interactions asynchronous, which complicates understanding and maintenance as well. Typically, restraint isn’t going to be exercised and powerful mechanisms will get used in unplanned and counterproductive ways sooner or later.
Message passing encourages bidirectional communication which in turn skews things towards stateful components. Is that the kind of complexity you want in your system, especially if it’s avoidable? Take UI rendering: you could do it in a top-down way where all the state is owned by the parent view, events are only sent in one direction (to the parent view) and the parent view re-renders the hierarchy of child elements as necessary. Alternatively, you could have each element maintain its own state, listen for relevant updates from all the other components and in turn broadcast its own updates. I would argue that the first approach is much easier to work with – but message passing encourages us to adopt the second.
Additionally, as message passing nudges the implementation to have more state and more stateful communicating parts, it works to undercut two great pillars of reliability: minimisation of state, and having a single source of truth. Maintaining and synchronising state provides a great breeding ground for bugs.
Side note: I like to consider whether I’m using the simplest mechanism that is sufficient to solve the problem. The more powerful a mechanism is, the more likely it is to be misused and to produce unforeseen consequences. There is more to say about it, but it’s a subject for a separate post.
So, based on my experience, I think that the downsides of introducing message passing often outweigh the advantages. It is an approach that should be used conservatively, only when simpler options are definitely not cutting it.
A powerful abstraction doesn’t eliminate the need for intentional design and always comes with caveats. On the other hand, intentional design may allow you to avoid opening the gates to unfortunate consequences for longer. You can get far by identifying independent components and relying on composition, minimising state, organising data processing into clearly defined sequential pipelines and so on.
But lastly: sometimes, what you need is a horse, even if it’s loaded with unwanted extras.
Some of the thoughts in this post were prompted by these good but only vaguely related articles: